你的位置:合规的炒股出资系统_合规的炒股出资软件_合规的炒股出资工具 > 合规的炒股出资软件 > 配资之家公司 只需将感知推理能力拆分,2B大模型就能战胜20B!国产新框架高效处理视觉任务
发布日期:2024-08-06 15:42 点击次数:69

只要把推理和感知能力拆分配资之家公司,2B大模型就能战胜20B?!
上海AI Lab联合南京大学、香港中文大学等机构,共同推出了一套两阶段框架——Prism。
这一框架不仅显式地解耦了视觉语言模型(VLM) 的感知和推理,还提供了一种更高效的处理视觉语言任务的方案。

最终让2B VLM和ChatGPT的组合表现出相当于10倍参数量VLM的性能。

Prism框架架构及功能
在解决复杂的视觉语言任务时,模型的感知和推理能力至关重要。当模型在基准测试中表现不佳时,我们如何区分问题源自感知能力还是推理能力?
针对这一问题,Prism框架将视觉语言任务处理拆分为两个独立阶段:
感知阶段: VLM作为感知模块遵循指令提取输入图片的视觉信息,并以文本形式输出
推理阶段: LLM作为推理模块根据提取得到的文本信息,结合输入文本生成回复
框架架构如下图所示:

Prism框架中用于引导VLM生成图片描述的指令可以是问题相关的,也可以是问题无关的。
VLM在框架中只用于视觉感知,而推理任务则由LLM解决。通过固定框架中的LLM,可以测试不同VLM的感知能力;相对应地,通过固定VLM并使用不同LLM,可以观察VLM的性能是否被推理能力限制。
除此以外,通过选定VLM和LLM,Prism具有解决视觉语言任务的能力。
利用Prism,团队对现有VLMs的感知和推理能力进行了解耦分析,揭示了若干有趣的发现。从这些发现中汲取灵感,团队在Prism框架内整合了专注于感知的轻量级VLM和一个专注于推理的强大LLM。
定量结果表明,这种组合在各种视觉语言任务中表现出卓越的性能和效率。
视觉语言模型感知推理解耦分析
固定Prism中的LLM为ChatGPT-3.5可以进行不同VLM感知性能的对比。考虑到对视觉输入依赖、数据泄露以及复杂性等问题的考虑,团队选择MMStar作为实验的基准。
实验使用了两类不同的指令。一是问题无关的通用指令,提前设定并固定;二是问题相关指令,其由问题需要关注的内容与通用指令拼接得到。问题需要关注的内容由推理模块LLM根据输入问题通过few shot输出。评估过程中最大输出长度设置为512,并采用贪心解码策略。
不同VLM在两类指令上overall的性能表现为:

在两类指令中,GPT-4o 表现出了最强的感知能力。
在开源模型领域,InternVL-Chat-v1.5 表现最佳。在问题相关指令的结果中,InternVL-Chat-v1.5 不仅在开源模型中表现最好,还微弱领先于 GPT-4v。
细粒度分析
闭源商用模型与开源模型的感知能力比较
GPT-4o作为闭源商用模型,在感知能力方面明显超过其他模型,并且可以熟练地处理各种感知任务。一些开源模型,例如 InternVL-Chat-v1.5 和 LLaVA-NeXT (Yi-34B),已经取得了显著的性能,接近 GPT-4v 和 GeminiPro-V 等闭源VLM的能力。其他开源模型由于感知能力有限,通常表现稍差。值得注意的是,MiniCPM-V-2 作为一款具有约3B参数的轻量级VLM,相比某些7B VLM表现出更好的感知性能。
感知能力的表现与端到端的性能表现的差异
除了以端到端的方式解决视觉问题外,Prism 还提供了一个替代管道,其中 VLM 仅用于感知。这两种方法之间的区别在于推理过程:前者在VLM内部进行推理,而后者基于使用外部LLM(ChatGPT)进行推理。这两种方法在MMStar上的比较如下图所示:
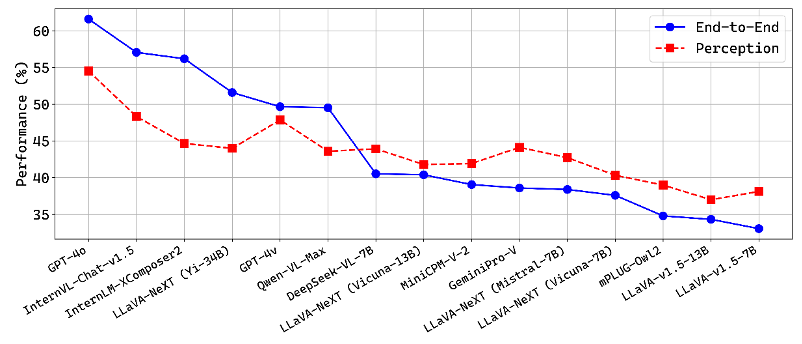
对于最先进的大规模VLM,如 GPT-4o 和 InternVL-Chat-v1.5,它们具有出色的推理能力,使用外部ChatGPT进行推理可能会降低整体性能。相反,对于大多数小规模的VLM,使用ChatGPT进行推理可以显著提高它们的性能,特别是在推理相关的VQA中,如下图所示。这一现象表明,小规模VLM的整体性能可能会受到语言模型的大小的严重限制。

ChatGPT 的推理能力是否限制了最先进的VLM呢?答案为是的。
将GPT-4o分别用作感知和推理模块进行解耦得到总体准确率为61%,与端到端GPT-4o性能61.6%几乎相同。
语言模型对感知能力的影响
评估过程中观察到当使用更大的语言模型时,LLaVA-v1.5 系列没有显示出显著的改进。这表明当使用相对低分辨率的视觉主干时,感知性能可能与语言模型的大小无关。
同时,LLaVA-NeXT 系列的定量结果表明,扩大语言模型会略微增强模型感知,特别是在使用问题相关指令时。其主要原因为:更精细的表达以及更适应于指令,如下图例子所示:

消融实验
团队针对Prism中的通用指令,推理模块LLM以及VLM视觉编码器对感知能力的影响做了消融实验,结果如下:
通用指令:对人工手写、GPT生成、思维链以及任务分解等不同类型指令的实验结果表明,即使差距并不明显,评估分析中所采用的指令是其中最有效的。
推理模块:比较不同的LLM推理模块的结果显示,ChatGPT在推理性能上表现良好,而GPT4则进一步提高了性能。开源模型 Llama3-70B-Instruct 表现出与GPT4相当的能力,表明开源模型在视觉信息推理中的潜力。
视觉编码器:关于VLM中视觉编码器对感知性能影响的实验表明,SigLip-SO400M 相比于 CLIP ViT-L/14 和 InternViT-6B 在实验基准上表现更好。
专注感知的轻量级视觉语言模型
团队从分析的结果中得到启发,使用ALLaVA数据训练了专注感知的轻量级VLM--PrismCaptioners ,并在Prism框架中与强大的LLM进行整合。
数据与架构
数据集
PrismCaptioners使用ALLaVA中的 ALLaVA-Caption-4V 和 Evol-Intruct-GPT4-Turbo-143K 作为指令调优数据。与QA格式的指令调优数据相比,利用描述性数据进行指令调优可以更好地训练VLM提取和表达视觉信息的能力。
模型架构
使用 SigLip-SO400M 作为视觉编码器,InternLM2-[1.8B/7B] 作为语言编码器,训练了两个不同尺度的视觉captioner,称为 PrismCaptioner-[2B/7B]。
模型性能
团队在MMStar, MMMU, MathVista,AI2D以及后三者的子集上进行了实验。子集选取的策略类似于MMStar。将PrismCaptioner作为Prism感知模块并接入ChatGPT或Llama3的性能表现如下表所示。公平起见,模型均使用单个图像作为输入,并将最大输出长度限制为512。

通过Prism整合VLM与LLM的方式相比于基于LLaVA数据训练的端到端baseline有显著的性能提高。同时,PrismCaptioner相比于另一开源caption生成模型ShareCaptioner也有更好的效果。
截至午盘,天力锂能、金杨股份、蓝海华腾、领湃科技、合纵科技等多股涨停。
华安期货表示,受到地缘政治影响,伊朗和以色列冲突加剧导致红海航线不稳定,持续推动盘面上涨。

对于7B版本,Llama3 的接入带来大幅性能提升,使组合PrismCaptioner-7B的方案成为极具竞争力的视觉语言模型,特别是在 MMStar 和 MMMU 上。对于2B版本,接入Prism后,它实现了与其十倍以上大小 VLM 相当的性能水平。这表明 Prism 能够提供一个强大而高效的解决方案,例如带有 ChatGPT 的 PrismCaptioner-2B,并展现了令人印象深刻的结果。

当最大输出长度设置为2048,并允许多张图像输入时(为每张生成描述并拼接),接入Llama3的方案在MMMU上取得了更高的性能,在开源领域优势明显,如下表所示:

此外,Prism允许灵活地结合多个VLM以增强感知。例如,简单地将GPT-4v和GeminiPro-V的输出拼接起来,即可在MMStar基准测试中的大多数指标上显示出了显著的改进,如下图所示:

此外,他们还跟GPT-4o进行了一个对比,发现仍有一定的进步空间。GPT-4o在空间感知推理方面能力更强,描述的更为详细和准确。

Prism框架的引入为视觉语言模型的研究和应用开辟了新途径。
通过有效解耦感知和推理配资之家公司,Prism不仅能够用于模型的分析和视觉语言任务的解决,还为未来的研究提供了新的方向。我们期待Prism在更多视觉语言任务中的应用,进一步推动这一领域的发展。
Powered by 合规的炒股出资系统_合规的炒股出资软件_合规的炒股出资工具 @2013-2022 RSS地图 HTML地图